1 引言
IEEE1394是在計算機與外設直接進行高速數據傳輸的串列匯流排,因其具有傳輸速度高、支持即插即用、支持多達63個設備級聯、以及設備間傳輸無需主機干預等特點,以至從其一出現就備受青睞。因IEEE 1394協議中的物理層可以在鏈路層不激活的情況下,作為中間節點而存在於1394網路中,物理層具有單獨存在的意義,因此應用中就有純物理層晶元、純鏈路層晶元以及物理層和鏈路層合一的晶元三種類別。
由FPGA實現應用協議是目前最普遍的晶元設計方法。在用VHDL語言兩個小FPGA晶元上分別設計出IEEE1394鏈路層和雙埠的物理層后,把這兩部分代碼合併到一個更大容量的FPGA上,並改進為三埠,看似非常簡單,但因FPGA電路的邏輯綜合,引腳到寄存器之間的延時等方面發生了變化,代碼移植髮生了問題。
由於物理層部分的移植過程中有增加埠,出現的問題較多,而鏈路層基本沒有變化,這裡主要分析物理層的設計部分。
通過對改進電路設計.分析代碼上的差別,從而闡述FPGA設計代碼規範化的重要性和一些技巧的應用。
2 IEEE1394物理層介紹
2.1 IEEE1394匯流排協議框圖
1394物理層的每個埠有兩對差分信號TPA和TPB組成,其中TPA包含TPA+和TPA-兩條信號線,TPB包含TPB+和TPB-兩條信號線,物理層通過判斷每個埠在自己發送的信號與對方發送的信號產生的線狀態來判別匯流排的工作狀態,當進人接收或發送狀態時,就進行數據處理,並與鏈路層進行數據交換。
1394鏈路層和物理層使用統一的系統時鐘,以保證數據的同步。鏈路層對物理層的匯流排申請和寄存器操作是單向的,由LREQ來控制。而數據則是雙向的,由控制信號決定數據的傳輸。鏈路層要實現發送數據的打包操作和接收到的數據的校驗判別及解包操作。
1394事務層則由具體的設備程序處理,其與鏈路層之間交換的是已通過校驗的有效數據包。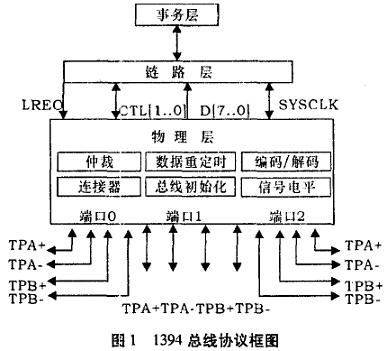
2.2 IEEE1394物理層的工作流程
1394物理層的每個設備沒有固定的節點號,是在使用時通過配置產生的節點號,設備間再通過這個節點號來識別數據的源與目標。其配置流程如下:
匯流排複位由設備上電、設備插拔、狀態超時、軟體控制等產生,它通過發送一個超過166us的BUS_RESET信號,保證所有的節點都能進入複位狀態。
樹標識是從葉子節點開始,按埠號由低到高的原則,通過子握手和父握手信號協商,把整個網路各埠的父子關係確定下來,也就是確定了整個網路的TOP結構(樹結構)。
自標識也是從葉子節點開始的,通過逐一向匯流排發送自標識包,來表明自己的身份,節點號從0開始,已經完成自標識的進人正常仲裁狀態,沒有完成自標識的,每收到一個自標識包,其節點號增l,這樣當最後一個節點(即根節點)完成自標識包發送后,網路上的每個節點都有一個唯一標識自己的節點號,這時自標識過程完成,所有節點都進入正常仲裁狀態。
正常仲裁則通過判斷匯流排狀態和鏈路層的匯流排請求,進行匯流排權的仲裁,包括優先權仲裁、公平仲裁等,只有通過仲裁獲得匯流排權的節點才可以向網路發送數據。
2.3 IEEE1394物理層的數據收發
在自標識完成後,獲得1394匯流排權的節點進入數據發送狀態,而沒有獲得匯流排權的節點進入接收與轉髮狀態。數據的發送比較簡單,直接向所有已連接的埠輸出信號即可,而接收則不同,一方面要從接收埠接收數據,另一方面要向其它埠轉發接收的數據,而這個轉發的數據,需要經過內部時鐘同步才能轉發出去。這樣就會有轉發延時的問題,考慮到匯流排上可掛接63個節點,因此,這個延時還不能太大,否則將影響整個1394匯流排權的仲裁,而導致系統崩潰。
3 移植前後的主要差異
3.1 晶元型號變化
由兩片EP1C6T144C8合為一片EP1C12Q240C8,總的I/O引腳減少,單一晶元的邏輯單元數加大,電路綜合變得複雜,綜合效果沒有晶元分開時好,另外合到一個晶元后,原本來自1394信號電纜的干擾基本只與物理層相關,現在更滲透到了鏈路層,反之,來自應用層的干擾原本主要影響鏈路層,現在卻影響到了物理層。
3.2 埠數增加
1394埠由2埠增加到3埠,信號數增加了12根,I/O資源變少,狀態判別邏輯變複雜,與信號直接相關的邏輯單元平均距離變長,也就是說信號延時變長。
3.3 鏈路層與物理層程序合一
程序合併后,調試難度增加,一是編譯時間加長,分成兩個單獨晶元進行電路綜合的總時間,要比合到一起后的時間短1/3;二是不能採取與標準LLC層、PHY層晶元分別調試的方式來簡化設計調試過程,因而導致問題更難定位。
4 移植過程中問題的解決
4.1 接收FIFO的處理
在移植前,是一個2埠的方案,移植后變成了3埠,按照原設計,先利用接收埠號(PORT)選擇相應的STRB和DATA輸人,再利用這個信號異或產生時鐘信號,接一個FIFO(見圖2),但運行中問題出現了,不是所有時間所有埠都能正常接收。
圖2 接收FIFO
實際上,擴充到3埠后,各引腳不是排列在FPGA的同一ROW或COLUMN,在電路綜合中,不同埠到FIFO的輸入路徑長度和方式都不一致,同時因為內部時鐘頻率並不比接收時鐘頻率高,不能在FIFO前對接收信號進行同步處理,只能使用組合邏輯,使得組合邏輯產生的毛刺影響了數據的有效性。
通過使用冗餘的辦法,把原來的共用FIFO改為每個埠一個接收FIFO(見圖3),這樣在每個埠能以最短路徑和很少的組合邏輯接到FIFO,而3個FIFO的輸出再由接收埠號來控制,此時FIFO的輸出是通過內部時鐘同步,這樣就解決了問題。
圖3 使用冗餘后每埠接收FIFO
使用雙時鐘非同步FIFO時,要注意Empty和Full輸出的時鐘對應問題,在本設計中,接收FIFO的接收時鐘是由信號XOR產生的,是臨時的,當接收數據停止時,時鐘不存在了,對應的Empty和Full失去了賴以動作的時鐘源,會一直保持下去,此時只有通過非同步清除的辦法才能清除這些信號。因為這個問題的存在,會出現數據已經讀完了,但Empty信號仍保持為低的情況,如果依賴Empty做判斷,就會出現死循環。
4.2 幀結束的判別
1394在接收數據幀的結束時,根據對方是否有連續數據幀發送,將分別收到DATA_PREFIX(10)或DATA_END(01)兩種情況,其再生的時鐘信號都為1,且最短的幀結束信號保持時間為4個時鐘周期。這兩個信號也會出現在數據中,但不會保持超過1個時鐘周期。這樣就可以利用DATA_PREFIX或DATA_END信號的保持時間來判斷幀結束。移植前是通過判斷FIFO空來處理的,因FIFO空與信號再生的時鐘相關,在幀結束時,信號再生的時鐘停止,需要用計數器進行輔助處理。因此移植後進行了改進。
在進行計數器設計時,一般採用同步清除的方式,這樣不至於因信號上一個小毛刺而導致計數器被清0,但在這個幀結束的判別中,卻不可以採用同步清除方式,因為接收的信號時鐘頻率雖和內部的時鐘頻率相同,但相位和占空比有差異,在用內部時鐘對接收到的信號進行計數時,會發生連續的數據信號被錯誤判斷而計數器未被清除,導致提早判定為幀結束。
-- RecvClk由Strb與Data異或產生
-- DATA_PREFLX和DATA_END異或產生的RecvClk皆為1
process(Pclk,RecvClk)
begin
-- 出現RecvClk為低,表示數據有變化,幀結束判別計數器清零
if RecvClk= 0 then
RecvEndCheekCount<=0;
elsif Pclk'event and Pclk='1' then
-- 開始接收后,進行接收狀態計算器
if RecvStartFlag='1' then
-- 收到RX_DATA_PREFIX或RX_DATA_END且保持3個周期,則幀接收結束
if RecvEndCheekCount/=3 then
RecvEndCheckCout<=RecvEndCheckCount+1;
end if;
else
RecvEndCheckCount<=0;
end if;
end if;
end process;
4.3 計數器處理
1394匯流排配置過程中有相當多的時間判別,如匯流排複位時間、複位等待時間、狀態超時等,都要使用計數器來解決。計數器有相應的計數條件和清零條件,而這些條件是與狀態機、接收到的埠狀態等相關的。
對於計數器的清零,有非同步清零和同步清零,非同步清零要求清零控制信號絕對的乾淨,因為一個小的毛刺,都會導致計數器歸零,除了非常特別的情況,一般不用非同步清除的計數器。
計數器的判別有用大於(小於)和等於(不等於)兩種方式,從理論分析來講,用前者應該比較保險,計數過頭了也同樣能判別成功。而實際上,因為大於(小於)的判別所消耗的邏輯單元要多,處理起來變得複雜,在計數值比較大時,反而容易出現問題,測試中發現,採樣等於(不等於)的比較方法要優於大於(小於)的比較方法。為了得到比較好的判斷結果,可以利用一些技巧,比如判斷連續的兩個值,這樣誤判的幾率就小很多。
signal TimerCount:integer range 0 to 1 5;
signal TimeOutFlag:std_logic;
process(Sclk)
begin
if(Sclk'event and Sclk='1')then
if(CountEnable='1') then
-- 當等於14或15時,置超時標誌,電路綜合時bit0未用到
if(TimerCount=14 or TimerCount=15)then
TimeOutFlag<='1';
else
TimerCount<=TimerCount+1;
end if;
else
TimeOutFlag<= 0;
TimerCount<=0;
end if;
end if;
end process;
4.4 邏輯鎖的應用
鏈路層(LEe)程序和物理層(PHY)程序,除了介面外,基本是獨立的,但在FPGA內部,由於資源有限,而且使用同一全局時鐘信號,在線路綜合時就出現了邏輯單元交叉的現象,這樣兩層之間的信號影響就加大。另外,各埠間的電路干擾也是存在的
為了減少這個相互之間的干擾,使用QUARTUS軟體所帶的邏輯鎖(Logic-Lock)功能進行處理。所謂邏輯鎖,就是在進行綜合布線之前,先把FPGA的內部邏輯單元進行預分配,把各模塊限制在一定範圍內,當QUARTUS軟體進行綜合布線處理的時候,它會首先在預分配的邏輯單元內進行相應模塊的布線處理。
實踐證明,使用邏輯鎖能有效地減少模塊間的相互影響,沒使用邏輯鎖前,鏈路層的中斷屏蔽寄存器被打開,應用層開始處理中斷數據,有時會出現接收的數據錯誤,甚至導致1394匯流排複位的現象,而使用邏輯鎖以後,這個問題就不存在了。不過邏輯鎖的應用要注意一定的規則,一是要判斷要加鎖的模塊大致邏輯單元數,邏輯鎖分配的單元數要有一定的余量,以保證模塊在綜合布線是不致線路太複雜;二是模塊盡量與其相應的I/O口靠近,減少布線的長度;三是有使用RAM或FIFO的模塊,一定要包含對應的RAM單元。
5 總結
FPGA的晶元代碼設計不同於CPU、DSP之類的代碼設計,CPU、DSP類的代碼設計,只要晶元引腳性能相同,程序移植過去就能正常工作,而FPGA的設計則不同,進行代碼移植后,其內部電路綜合結果將因晶元的邏輯單元布局、使用的編譯器版本等很多相關因素而發生較大的變化,因此,FPGA代碼的移植相對要難得多。只有按照一定的規則進行代碼優化,而不是依賴於晶元本身的特性來拼湊實現所需功能,才能編製一個可移植的FPGA代碼。
時序同步是FPGA設計的關鍵,能用時序邏輯實現的,盡量採用時序邏輯,能同步處理的就不用非同步處理。時序邏輯能有效地消除因組合電路門延遲產生的毛刺對邏輯的影響,當然這裡有個前提條件是兩級時序電路之間的組合電路門延遲不能太大,因為延遲太大時,在時鐘沿到來時,組合邏輯的輸出仍是不穩定的,時序鎖存後會出錯,因而時序電路兩級中問的組合電路是影響速度的關鍵,例如用相等判別要比判別大於(小於)速度快。
在必要的時候,用空間換時間的冗餘設計是很有效的,如果通過冗餘,能大大降低邏輯的複雜程度,就能提高信號處理速度和增強電路的穩定性。如前面的單FIFO改成三FIFO設計,就是利用了這個思路,把組合邏輯部分簡化了,解決了干擾問題。多時鐘系統中,使用FIFO來解決同步問題是最好的辦法之一,尤其是兩個時鐘頻率相差不大的情況,用FIFO來同步可能是唯一的辦法。不過,使用非同步FIFO,輸入和輸出之間會有8個時鐘(輸入時鐘)的延遲,對應與之相關的電路,要考慮這個延遲,否則,控制信號和數據信號不協調,同樣會工作不正常。
在FPGA設計中,除了晶元差異和程序設計不同影響最終結果外,編譯系統的差異,也會影響最終結果。這個是與基於指令集的CPU、DSP等完全不同的。不同的編譯系統,在進行電路綜合是採用不同的演算法進行優化處理,同樣一個功能,編譯結果可能完全不同,如使用邏輯門的數量、信號的路徑等都有差別,因為不同綜合結果電路中延遲的差異,會導致性能和功能上的差異。因此,在電路設計中要盡量使用系統元件庫和電路模塊化的處理,另外,要合理利用一些編譯系統的功能,對電路進行一下優化、抑制處理,尤其是象邏輯鎖這樣的工具,它能使得一個內部模塊象一個獨立的晶元一樣包含在電路中,對電路的綜合效果非常有好處。
[admin via 研發互助社區 ] 從1394 VHDL代碼移植看FPGA設計已經有1858次圍觀
http://cocdig.com/docs/show-post-43148.html
