Altera FPGA的速度沒有Xilinx的速度快,錯!當然這種非對稱的結構,你必須有一定的了解,才可以更好的利用.也就是要遵循:
Altera至此以後,一直沿襲這種結構規劃.因此,如果你想有效利用好Altera的產品,就應該遵守這個規則.但是要說明的,真正能體現性能的東西,也許就是你意識不到的一種小東西,就是簡單的就是最好的.Altera正是憑藉這個簡單而高效的布局結構實現了今天的王道!昨天說到這裡今天繼續開始. 又有很多時候沒有提Lattice,在1998年的時候,Lattice和Altera同時都有成為PLD霸主地位的意圖.什麼可以證明呢,那就是誰最先推出可以ISP的宏單元超過1000個的PLD. 當然在這個遊戲過程中,Altera有一些變化,他有效的將他的Flex8000的布局結構和他的MAX7000進行結合. 從而實現了在PLD規模擴大的同時可以實現:
Altera在推出他的最大的9560,具有560個宏單元的PLD,登上了無可爭議的PLD冠軍獎台.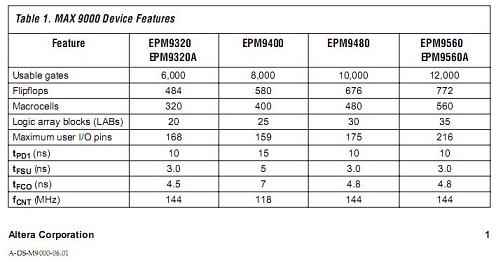
當然有的人要說,Lattice有推出1000個左右,怎麼不提呢. 正是因為這點,導致Lattice步入歧途. 實際上,FPGA世界的遊戲規則已經改變了.
MAX9000的成功得益於以下的細微結構.這個時候Altera又一次將自己的顆粒度進行了擴容. 有16個宏聚集在一起,在實現更多位的加法,控制,超前進位,大的多選一的應用中,可以將這些模塊一次性放入一個LAB,同時在LAB內完成路由. 現在已經露出一種跡象. 大的規模要有,但是速度的需求已經開始了. 所以在FPGA,CPLD的應用中,又有了新的裁判規則,你不僅要夠大,還有夠快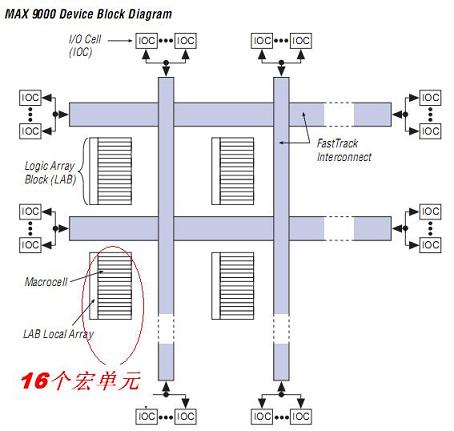
這個時候的非同步設計還是非常的多,而且板子上晶元間信號的互聯也多起來了,能夠有效縮短Tsu已經成為一個重要的話題. 實際上,就是在IOC上要有DFF,來進行快速鎖存,同時也為所有進入CPLD的匯流排信號進行第一次整理. 怎麼實現很多的非同步設計,看了下面,你就明白了. 第1點,就可以用所有信號的函數輸出作為clk,第2點,有效的將沒有用完的資源很好借用給其他的宏,來用對稱的結構實現非對稱的應用!用簡單的結構,應變不斷的變化.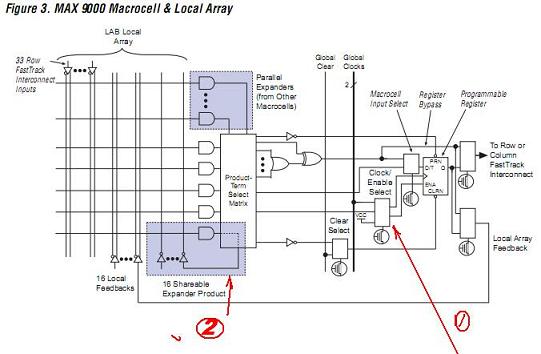
縱觀當時其他的PLD,在結構上就落後很多了. 你想,讓你和姚明來爭籃板球,如果你沒有人家的身材,贏他恐怕也是嘴上的功夫了.
這個時代的強者就是---誰有最多的邏輯資源,或者memory,誰就是老大.
上面說到Lattice已經在極力擴大自己的身材,但是他不是靠結構上的改變,而是Lattice收購了Vantis,也就是AMD的一個做PLD的小部門. 當然在當時,AMD的Mach就這樣併入了Lattice的家族. 新的問題就出現了. 好比我們現在有人用什麼大靈通,小靈通,GSM,CDMA,是有百花齊放的感覺,但是Lattice就像變成了解放前的蔣介石,沒有辦法很好的用一套工具來統一使用不同的器件. 而且本身Lattice自己當時的工具也是3個獨立的工具拼湊在一起的. 那個年代,用過Tango,後者Orcad的人都知道,他們的圖形輸入是第一名的,但是和MaxplusII比起來,自動識別對象鏈接,以及和Office 95類似的快捷鍵,用過Maxplusii的人,讓他們轉用Viewlogic等workoffice等,簡直簡直就是抹他們的脖子. 還有當時Lattice的銷售團隊,總是宣揚他們是最好的PLD,有些人竟然有 "我認為64KROM,就可以應付未來所有的軟體需求" 這樣的論調,認為PLD必將擊敗FPGA,事實上,市場的殘酷,告訴他們那是個很冷的冬天. 於是他們又一次在2000年左右,如同水淹七軍一樣的結局,又急忙掉轉船頭,收購了ORCA,可惜了ORCA是出自Lucent的一條好漢,由於沒有良好的軟體支撐,使得每個工程師必須像哪吒一樣. 對了,怎麼會像哪吒? 因為你必須有三頭六臂,如果你公司有些產品需要從32個宏單元到2000個LE的FPGA的應用,你就必須學習3種工具來適應它. 你想想,你是不是一定要像哪吒呢!
再次談結構以及方法學!
這裡開始講些看來與我們主題有點不搭界的東西.
1--兩個人相遇,只握1次手
2--三個人相遇,每人都握一次,握3次手
3--4個呢?就是2的結果加3次,6次手
4--5個呢? 10次手.
5--16個呢,.......天,不少於...
PLD就是這樣的產物,當邏輯……你會發現,路由的面積都超過了有效的邏輯面積. 而且,越大越糟糕. 可以下載這個簡單的PPT來發現一些小問題!
advantagestruc.zip
什麼樣的數目比較好,對於PLD的宏單元數目
實踐是檢驗真理的唯一標準. 有人說了,256個是最好的結構,為什麼呢,不然怎麼那麼多廠商都是在這個範圍呢. 實際上,他是由經濟規律決定的,就是當時用256個的宏單元結構的晶元的面積,和他們賣出的價錢,比較符合當時這些上市公司的利潤要求,所以.....就以這個最流行了.
但是Altera進行了很好的變通. 中國有句話叫"玄之又玄,妙之又妙",什麼是玄? 玄就是變通的意思,也是變得意思. 實際上萬事萬物都是相通的. 那Altera就像我們的學校一樣,每個年級分不同樓層,每個樓層分不同班級,每個班級上不同的課. 但是用行列塊的方式,達到既有規模,也有位置相關性. 而且路由的面積也不會大到賺不到錢. 實際上你自己觀察,近10年 ,Altera的FPGA的主要框架是沒有變化的!
Xilinx 的FPGA結構,實際上,有一個5200系列,很向Altera的Flex6000,但是沒有多久這個東西就不見了. 總之,Xilinx的結構屬於稱為 "孤島式"結構,就是CLB在中間,路由圍著這個孤島. 在一定的密度的時候 ,這種結構也還是不錯的,當然有一個很重要的結構就是,他是全對稱的. 就是Xilinx的晶元的邏輯上資源的密集度是上小左右對稱的. 這個有好處,但是也有壞處. Altera的呢,是橫向資源豐富,縱向資源相對較少,但是,在局部的橫向上,又可以進行級聯LE,DSP,Carry chain 等等. 好了,給大家舉個簡單的例子.
孤島式的結構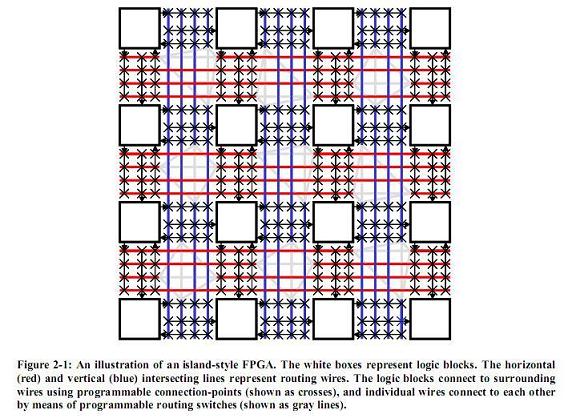
Altera 的類似的結構,但是顆粒度大,從這張圖,應該可以看出altera在橫向資源是很豐富的. 就是同一行的資源遠多於同一列的. 輸入輸出就更是了. 當然,這個和管腳的封裝腳的出位不是絕對一一對應的.
Stratix的出現
在2001年,Altera推出了他們最偉大的產品,Stratix. 當時FPGA的競爭規則又發生了改變
但是上面這三點,都不是決定性的. 這個時候,數據通信對背板走線和背板匯流排要求已經很高了. 實際上FPGA也搖身變為系統級晶元了.
你不僅要有大的邏輯規模,合理的memory尺寸,相對豐富的時鐘資源,還有就是要有高速的Serdes,缺少一項,你都會在系統級的應用中只能是亞軍!
剛才說了系統級的應用,已經成了FPGA最殘酷的競爭市場. 那麼PLD呢,怎麼樣了,實際上自然總是物競天擇!PLD已經變為這樣的幾種應用了
就像一個國家的海軍一樣,PLD已經成為一些簡單的驅逐艦,馳騁大洋的,可以跨海作戰的,絕對不是這樣的產品可以涵蓋的. 所以,你今天喝可樂的時候,不會有太多的選擇. 偶爾的一些牌子如同過眼煙雲,很快就彈出你的視線了.
是的,十年前我的很多朋友,有在Quicklogic,有在Cypress,現在還有一些在不斷出產品的公司,當然,只能是劍走偏鋒. 做些細分市場還是可以繼續的.但是三國鼎立的形式已經是不可撼動的事實了.
北京和深圳的差別?
你到過我們的首都北京嗎?到過我們的特區深圳嗎?這樣打比喻是因為我在深圳和北京都旅遊或者工作過.實際上我也只是想借用這兩個城市的布局來做個比喻.
北京是比較對稱的城市,有東直門,西直門. 有東單,西單等等. 總之,他的布局就像Xilinx,無數個衚衕就是像Xilinx圍繞在CLB的路由線. 這些資源在Xilinx的數據手冊中有: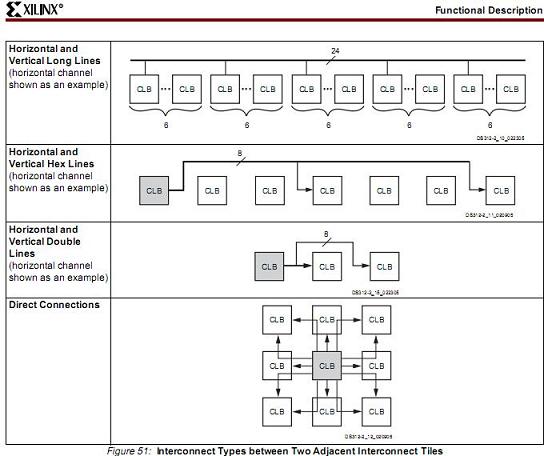
但是這些衚衕間的聯線並不是十分充足. 特別是到了規模很大的時候.Altera的呢?在深圳的人,如果你不認路,很簡單,只要你走到"深南大道,濱河大道,北環大道"上的任意一條,你就可以再從這些大道到你要去的地方. 但是前提是 ,這3條大道的寬度要夠. 提示一點,這三條大道也是東西走向比較平行的. 而且整個深圳也是一個東西走向的城市,地下再有一條地鐵,在同樣資源的情況下,布通率,和平均車速是非常好的. 而北京的地鐵,是環形的.資源上不如深圳的利用率高,這裡無意於評價城市規劃和道路設計. 只是比喻.
Altera的FPGA就是如同深圳的道路,他可以讓你從列上很自如的轉到寬闊的行上,然後再到達你的目的地. 所以,可以告訴你一個經驗.
另外,這個地方也有顆粒度大帶來的好處. 所以,有些原來看似不精細的地方,卻在規則改變后,就變得反而是犀利無比.
運籌學也是很重要的!
經常有這樣的情況,大家選擇FPGA的時候,就開始翻看每種FPGA的選型手冊,然後對資源表. 有的甚至直接說:我這個是10萬門的. 你的那個是6萬門的,實際上,這些都不是很正確的評估. 如同有人說,我家的房子4室兩廳,你家的房子3室1廳雙衛生間. 到底哪個更大呢? 到底哪個更節能呢. 廚房熱水器之間離得很遠又是問題.
所以說,學會正確的評價資源是很重要的. 這個時候還要參照他的結構!!板式的,還是磚混的!!!
可能你還聽說過一個使用面積的問題. 實際上,有的房子看起來大,走道,不規則的布局,導致很多的地方都不能用!下面看個例子: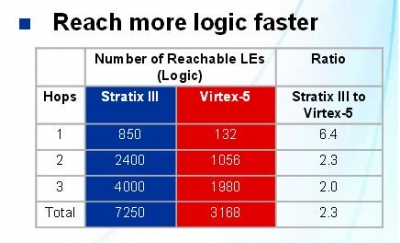
左邊的Hops代表跨一步的意思,就是路由轉換一次的意思. 這個表什麼意思呢. 就是說在S3的路由過程中,每個路由在第一次,就可以覆蓋850LEs中的一個,V5是132. 如果你的邏輯,經過4跨,同樣的路徑覆蓋的區域A的是X的2倍. 代表什麼呢?
當然還有一些好事者,例如 (http://www.opencores.org) 有很多公開的opencore,大家可以將它們同時嘗試放在A,X,L,看誰放的多,放的快,系統延遲更小. 這方便數據就不多說了,可能都成為一門學科都不一定,因為不同的比對都有benchmark的不同標準. 最終我們應該很清楚的看到.
結構真的是很重要,我們能幹,也要看是否站在巨人...
不過呢,很多時候,我們的朋友基本上都說: 結構和我無關,我要學好VHDL,我要....codingstyle. 這個設計屬於系統工程!
FPGA的真正命門和Know How實際上,能做FPGA的公司太多了,但是能將我們的設計通過演算法成功放到這個晶元上,而且算出正確的時間和你的模擬要求的. 就不多了,說的難聽點. 有些領域甚至是沒有亞軍的競爭!選擇小規模PLD,那些,不是太重要的問題. 本身就不夠養活一票人的產品.
Cyclone III 與 Spartan3 的對決--蘋果對蘋果?
目前,很多人都基本上對於新的中檔設計都會集中在這個系列的競爭中,換言之,在中國目前以成本為導向的第一要求下,實際上中小公司的產品選用80%是集中在這裡.
經常有人說,為什麼你們的LEs數目相同,價格很不同. 做些解釋,一家之言.
有一點要說,那些所謂我的是多少系統門的比較方式,是典型的大忽悠模式
比較產品有很多benchmark. 這裡列舉一些. 不全的地方,可以大家補充.
所以不是簡單說我的蘋果和你的蘋果一樣. S3隻有銷價處理才是真正的出路.
如果你知道了結構,你會發現什麼呢?
實際上,Altera一直在橫向布線資源上濃墨重彩,因此,在Cyclone一代系列的時候,如果你的設計模塊放在一個比較長的區域就更加容易跑出好性能.
如: 5行,5列的一個資源放置,不如在一個4行7列的區域中更好發揮性能.
到了CycloneII,可能就是接近1:1.2的樣子.
Statix,基本上接近正方形.
其他的你可能需要實驗一下. 畢竟這個是動手的科學. 而且,每家FPGA廠商,在關鍵布線資源方面,都是秘而不宣. 這個也是為什麼Synplicity要另嫁豪門的原因!因為自己沒有辦法得到這些資源. 而綜合技術已經被FPGA廠商步步緊逼了!
Cyclone III的巧合.
Cyclone III的誕生,可以說也是有劃時代意義的.但是贏得偶然,其中已有些必然.下面來說說這個東西.
前面有人說過Xilinx的V5不錯,但是如果說V5和StatixIII帶有Serdes的產品同時間面世的話. 作為設計者,可能問題就來了. 太多選擇就是難以選擇
StratixIII 速度快,布線好,但是沒有Serdes
V5速度布線都不錯,出來的早,快人一步也是賣點.
但是呢?這兩個產品都很貴.
由於Xilinx很重視高端用戶,因此他們也認為Spartan3可以解決目前很多需要,這個也對,因此他們計劃在45nm左右推出Spartan的升級產品.
Cyclone III,正好趕上高端DSP處理市場的繁榮,以前Xilinx的website上面也有這方面的跡象. 號稱Xilinx也是一個DSP的公司. 這個也要得益於其他生態鏈軟體系統的發展,Matlab的simulink,
另外,目前的有線系統中對Memory的需求也非常高,作為有效的緩衝也需要更多的空間.
舉例來說,一個Video的應用. 需要一些濾波或者其他的應用,那需要的FIR的Tap數目實際上是可大可小的. 但是以前他們認為邏輯資源的比例太多於DSP的建立資源. 導致很多設計用30萬個LE的資源的FPGA,實際上,Logic資源利用在30%左右,而Memory仍舊顯得很局促. 還有一個就是用DDR2的設計也有增多的趨勢,
還有就是中型設計的比重已經上升很快,就是在3年前,大家很多集中在6000個LE左右的資源. 而緊接著的趨勢是200個500個左右的資源和10000個LE資源的迅速兩級化. 另外一個增長就是50000個LE左右的區間,而這部分長期以來都是Stratix和v4,v5的傳統空間. 可是現在由於memory,mulitiplier的增加,導致系統性能也可以用CycloneIII實現資源換取速度和效率的方案. 因此CycloneIII的資源也能利用低價格來和高端FPGA分一杯羹.
但是CycloneIII儘管有價格優勢,邏輯和memory的優勢,可是在Serdes的應用上,還是一片空白. 這也是大家覺得他的缺憾所在.
總之,CycloneIII和Spartan3 DSPA系列的推廣,已經有一個暗示的信號,就是
以多塊,大容量memory,Serdes可選的特點將成為新的中級FPGA市場的標杆了.
為什麼Cyclone,或者說Altera的粗顆粒有一定的好處?
大家都知道,Altera的結構可以說看起來是大開大合,實際上是粗中有細.
以前一個LAB有8個LE,大家都可以理解,後來又發展成有10個LE,有16個LEs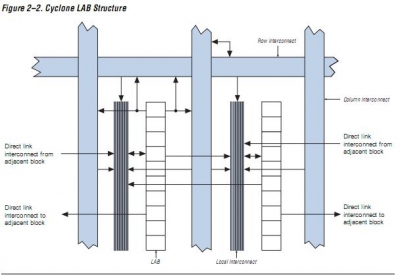
如果你有一個計數器,假定在Cyclone里和Spartan裡面跑,Cyclone和Spartan在做8位計數器方面應該是不相上下,但是,當在16位計數器還要跑同樣的速度,而且保證路由資源最簡單的時候,Cyclone的優勢,或者說A家的優勢就來了.
大家都知道,計數器就是進位翻轉的傳遞鏈路是他性能的關鍵路徑,換句話說,16位的計數器,就是兩個8位計數器的級聯,唯一區別的複雜度就是8位的傳遞時間如果是8x,那16位的就是16x了. 用另外一種方式來思考:
8位的計數器,在到達FE這個數字的時候,就用一個DFF進行一次隔離,提前一個時鐘節拍將進位準備好,這樣就將一個16位的計數器的複雜度降低到了8位一個樣子. 可是原本Cyclone的LAB就有10個LE,因此為了防止毛刺的問題以及剛才需要一個插入的DFF,就剛好放在一個LAB裡面,LAB裡面的路由是最快的,而且編譯基本不太花時間. 同時也為設計流水線的解碼技術,提供兩級的DFF延遲,但是這些全部做到了放在一個LAB.
大家回顧一下我們的設計,不就是計數器,加多選一,什麼FSM就是那幾個玩意來回的組合. 然後中間加流水,再平衡流水寄存器之間的路由. 沒有新的發明,只有新的組合. 但是Altera這樣的結構就相對來說..哈哈又要吹一下牛皮了.
過去10年FPGA產業的發展和FPGA廠商的挑戰?
過去10年,FPGA產業發生了些重要變化,簡要3點:
===============================
[admin via 研發互助社區 ] FPGA三國志-第二篇/結構篇已經有2603次圍觀
http://cocdig.com/docs/show-post-43032.html
