摘要 在開發數據流設備的驅動程序時,採用中斷驅動的I/O方式結合緩衝區的使用,可以將數據的接收和系統調用read隔離開來,提高設備在系統中的運行效率。本文在討論uClinux下中斷處理程序和底半部分的開發的基礎上,以一種電信E1線路和乙太網互聯設備上數據流設備為例,講述中斷驅動的I/O方式的驅動程序開發。主要過程是在中斷期間填充數據到緩衝塊,並用鏈表將緩衝塊串接起來;在系統調用read期間從緩衝塊取走數據,再將緩衝塊放到自由鏈表中備用。涉及驅動程序中常用的阻塞式I/O和自旋鎖等技術應用。通過使用上述多種技術開發的數據流設備驅動程序,確保系統穩定高效的動作。
引言
在32位微處理器逐漸成為嵌入式系統主流的同時,嵌入式應用也變得越來越複雜。許多嵌入式系統都不得不藉助於專用的操作系統來支撐自己的應用。uClinux作為類Unix操作系統,繼承了Linux的各種優秀的品質,成為首選的嵌入式系統的操作系統。
為自己的設備在操作系統下添加驅動程序,是嵌入式設計必不可少的部分。針對不同的設備類型,選擇合適的驅動程序的模式,同樣也是十分重要的。通常的設備驅動採用直接I/O的方式,如存儲器、看門狗等;而對於象網路這樣的數據流設備的驅動,則應該用到中斷機制。
本文以uClinux為背景,以一種數據流設備為目標,介紹中斷驅動的I/O設備驅動的開發。
1 應用背景
1.1 硬體描述
本文介紹的驅動程序是應用在一種電信E1線路和乙太網互聯設備上的。它是旁路接收E1數據並將其發送到乙太網的某一台伺服器上,在伺服器上對E1的話路和信令時隙分析。
該設備中的處理器是採用三星公司出品的網路型ARM處理器S3C4510B。E1線路介面採用Dallas半導體公司的專用El介面單元(LIU)晶元DS2148,它完成波形整理、時鐘恢復和HDB3解碼。DS2148將整理后的E1數據流送給一片Altera公司的Cyclone系列的FPGA(EPlC3T144C8),它將串列的E1數據流存入到FIFO,再通過ARM的32位外部匯流排將數據傳送給ARM。ARM將數據打包通過乙太網發送到伺服器上。圖1所示是本系統的硬體框圖。本文主要介紹接在ARM的外部匯流排上的FPGA,在uClinux下的驅動程序中斷機制的設計。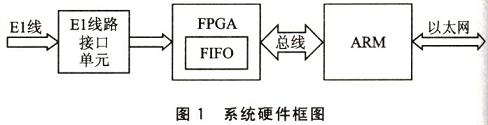
1.2 硬體連接
S3C4510B處理器和FPGA的連接電路如圖2所示。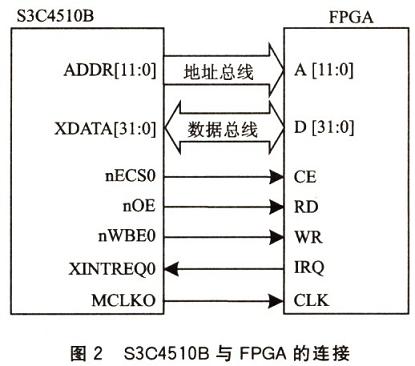
1.3 FPGA內FIFO的結構
在FPGA內部設置了兩個FIFO。為了防止ARM和FPGA操作的衝突,ARM和FPGA對兩個FIFO操作採用乒乓方式,這樣ARM和FPGA就可以同時操作不同的FIFO,而不需要等待。FIFO的大小是4096位,能容納一個E1復幀的數據量。當FPGA將一個FIFO填滿后,會用中斷的方式通知ARM來讀FIFO,同時FPGA會置內部的F1FO狀態寄存器。FIFO)狀態寄存器命名為fpga_imf,是一個32位的寄存器,用其中某幾位置“l”,表示對應的FIFO需要讀取。
2 軟體設計
中斷驅動的I/O是指,輸人數據在中斷期間被填充到緩衝區內,並由讀取該設備的進程取走緩衝區內的數據;輸出緩衝區由寫設備的進程填充,並在中斷期間取走數據。數據緩衝可以將數據的發送和接收與write及read系統調用分離開來,提高系統的整體性能。下面是uCllnux下的中斷程序的設計。
2.1 uClinux下的中斷程序
在uClinux系統中,通過調用下面這個函數向系統申請一個中斷通道(或中斷請求IRQ),並在處理完以後釋放掉它。
mt reqLIest_irq(unsigned int irq,void(*handler)(int,vold*,
struct pt_regs*),unsigned 10ng flags,const chat*device,
vold*dev_id);
void free_irq(unstgned int lrq,VOid*dev_id);
其中,irq是中斷號。在本系統中它對應於S3C4510B的21個中斷源。這裡用的是中斷源O。handler指向要安裝的中斷處理函數的指針。flags是一個與中斷管理有關的各種選項的位元組掩碼。device傳遞給request_irq的字元串,在/proc/interrupts中用於顯示中斷的擁有者。dev_id指針用於共享的中斷信號線。函數的返回值為O時表示成功,或者返回一個負的錯誤碼。函數返回一EBUJSY通知另一個設備驅動程序已經使用了要申請的中斷信號線。下面是FPGA的設備中斷申請函數。這個函數是在驅動中的fpga_open函數中被調用的。
int fpga_open(struct inode*inocle,stuct_file*file){
int result;
result=request_irq(FPGA_IRQ,δfpga_isr,SA_INTER-RUPT,″fpga″,NULL);
if(resuIt!=O){
printk(KERN_INFO”Can not register FPGA ISR!\n”);}else{
printk(KERN_INFO″FPGA ISR Register successfully!\n”);
}
}
在申請了中斷通道后,系統會響應外部中斷0,而進入中斷處理程序。中斷處理程序的第一步是要先清除S3C4510B的中斷懸挂寄存器的外部中斷O位。這是為了讓FPGA可以產生新的中斷。在uClinux系統中是調用下面的宏來實現的。
#deflne CLEAR_PEND_INT(n) IntPend=(1<<(n))
中斷處理程序功能就是將有關中斷接收的信息反饋給設備,並根據要服務的中斷的不同含義相應地對數據進行讀寫。所以FPGA的中斷處理的主要任務是,讀取FPGA中FIFO狀態寄存器的值,獲取需要讀取的FIFO的信息並安排接收數據。在程序中用到了系統提供的inl函數。
unmgned mt status
status=inl(FPGA_IMF);
中斷處理程序的執行應儘可能的短,而從FPGA中接收數據,一次必須讀完一個FIFO及128字。這是一個需要較長時間的外部I/O操作,所以把這個操作放到中斷處理的底半部(bottom-haIf)來完成。下面介紹中斷處理的底半部的設計。
2.2 BH機制
底半部處理程序和上半部最大的不同就在於,在執行BH時所有的中斷都是打開的,所以說它是在“更安全”時間內運行。2.4版本的uClinux內核有三種機制來實現底半部的處理:軟中斷、tasklet和BH。在這裡選用了較為簡單的BH機制。
BH機制實際上是一個任務隊列,中斷處理程序將要處理的任務插到特定的任務隊列中等待內核執行。內核維護著多個任務隊列,但驅動程序只能用前三種:
①tq_scheduler隊列。當調度器被運行時,該隊列就會被處理。因為此時調度器在被調度出的進程的上下文中運行,所以該隊列中的任務幾乎可以做任何事。它們不會在中斷時運行。
②tq_timer隊列。該隊列由定時器隊列處理程序(timertick)運行,因為該處理程序是在中斷時問運行的。該隊列中的所有任務就也是在中斷時間內運行的。
③tu_lmmediate隊列。立即隊列在系統調用返回時或調度器運行時儘快得到處理的(不管兩種情況誰先發生了)。該隊列是在中斷時間內得到處理的。
隊列元素由下面的結構來描述:
structtq_struct
structq_struct*mext /*激活的BH的鏈接表*/
unsigned 1ong sync; /*必須初始化為零*/
void(*outine)(vold*); /*調用的函數*/
void*data; /*傳遞給函數的參數*/
};
上面的數據結構中最重要的欄位是rotltine和data。將要延遲的任務插入隊列,必須先設置好結構的這些欄位,並把next和sync兩個欄位清零。結構中的sync標誌位用於避免同一任務被插人多次,這會破壞next指針。一旦任務被排人隊列,該數據結構就被認為是內核“擁有”了,不能再被修改。
在FPGA的驅動中,定義了一個任務隊列元素用於完成底半部分:
struct tq_struct el_task;
unsigned int el_line;
el_line數組用來保存傳遞給任務的參數。在打開FPGA時要對任務隊列結構賦值:
el_task.routine=fpga_bh;
e1 task.data=&e1_line:
上面的fpga_bh是底半部分處理函數void fpga_bh(unsigned int*line)的函數名,el_line是傳遞給fpga_bh函數的實參。
與任務隊列有關的還有下面的函數:
void queue_task(struct tq_struet*task,task_queue*List);
正如該函數的名字,本函數用於將任務排進隊列中。它關閉了中斷,避免了競爭,因此可以被模塊中任一函數調用。FPGA的任務被插入到tq_immediate隊列中,所以,list被賦值為&tq_immediate。
當某段代碼需要調度運行下半部處理時,只要調用mark_bh即可:
void mark_bh(int nr);
這裡,nr是激活的BH的類型。這個數是在頭文件<linux/interupth>中定義的一個符號常數。每個下半部BH相應的處理函數由擁有它的那個驅動程序提供。
完成任務隊列元素設置后,中斷處理函數中就可以啟用BH機制。在讀得fpga_imf的值后將其賦給el_line,然後調用queue_task將任務插入到tq_immediate隊列中,再調用mark_bh(IMMEDIATE_BH),啟動底半部分處理。到此,中斷處理程序就可以退出了。
2.3 底半部分處理程序和緩衝區
uClinux操作系統退出中斷處理程序后,會立即將tq_immediate隊列中任務投入運行,其中也有fpga_bh函數。在進入fpga_bh同時,系統會將el_line的地址作為實參傳遞給形參line。也就是將FIFO狀態寄存器(fpga_imf)的值間接傳給了底半部處理程序。底半部分程序中會檢查這個值的每一位,據此決定需要讀的FIFO。
從FIFO中讀上來的數據都是存放在內核的緩衝區中的。因為每一個FIFO的容量是一個E1的復幀,所以內核的緩衝也是以E1復幀的大小為一個緩衝塊。緩衝塊用鏈表串連起來。緩衝單元的數據結構如下:
struct buf_struct{
struct list_head list; /*鏈表頭*/
unsigned int buf_size; /*數據塊的大小*/
unsigned int*buLhead; /*緩衝塊的指針*/
unsigned int*buL_curl /*緩衝塊當前指針*/
};
buf_size說明了數據塊的大小。這是一個以“字”為單位的數值。緩衝塊在內核堆區開闢,buf_head指向實際的緩衝塊的首地址,而buf_cur指向緩衝塊中正在操作的單元。為了使用鏈表機制,驅動必須包含頭文件<linux/list.h>。其中定義了list_head類型結構:
struct list_head{
struct list_head*next.*prev;
為了訪問緩衝塊鏈表,還要建立一個鏈表頭,在驅動 中定義全局變數:
struct list_head read_list;
鏈表頭必須是一個獨立的list_head結構。在使用之前,必須用INIT_LIST_HEAD宏來初始化鏈表頭:
INIT_LIST_HEAD(&readlist); I
Linux系統提供了鏈表的操作函數,在頭文件<linux/list.h>中:
list_add(struet list_head*new,struct list_head*head); /*在鏈表頭后插入一個新項*/
list_add_tail(stuot list_head*new,struet list_head*head); /*在鏈表尾部添加一個新項*/
list_del(struet_list_head*entry); /*將給定項從鏈表中刪除*/
list_empty(struct list_head*head) /*判斷鏈表是否為空*/
list_entry(struct list_head。ptr,type_of_struet,field_ name); /*訪問包含鏈表頭的結構*/
其中list_entry的作用是一個1ist_head結構指針映射回一個指向包含它的大結構的指針。ptr是指向structlist_head結構的指針,type_of_struct是包含ptr的結構類型,field_name是結構中鏈表欄位的名字。如可以用這個宏將指向數據緩衝塊的鏈表指針(readl)映射為緩衝塊結構指針(buf):
struet buf_strcut*buf=list_entry(real,struct buf_struct,list);
底半部分處理程序中,內核緩衝塊是動態分配的。因為驅動程序是內核的一部分,所以在內核堆區開闢緩衝區就要用專用的函數,在頭文件<linux/malloc.h>定義了如下函數:
void*kmalloc(size t size,int flags);/*在內核堆中分配size大小的空問*/
void kfree(void*obi/*釋放kmalloc分配的空間*/
kmalloc函數的第1個參數是size(大小),第2個參數是優先權。最常用的優先權是GFP_KERNEL,它的意思是該內存分配是由運行在內核態的進程調用的。有時kmalloc是在進程上下文之外調用的,比如在中斷處理、任務隊列處理和內核定時器處理時發生。這些情況下,current進程就不應該進入睡眠狀態,這時應該就使用優先權GFP_ATOMIC。
不要過於頻繁地用kmalloc在內核堆中分配空間,因為在分配空間時可能有中斷到來,這樣是不安全的。在驅動中建立另一個鏈表用於回收使用過的緩衝塊。在驅動中用free_1ist作為回收緩衝塊的鏈表頭:
struct list_head free_list;
這樣就存在兩個鏈表:一個是裝載著數據的鏈表,一個是已經使用過的緩衝塊的鏈表(稱為自由鏈表)。那麼只要自由鏈表中還有表項,在需要緩衝塊時就可以直接從自由鏈表中取出一個使用,而不用kmalloc再去分配。
2.4 阻塞型I/O和自旋鎖的使用
在驅動程序中,read的工作是將內核緩衝區中拷貝到用戶空間。在進行這種操作時有兩種情況是應該注意的:
①當read時發現讀鏈表是空,也就是還沒有數據可讀。
這種情況下,可以讓read立即返回一EAGAIN,告知用戶進程沒有讀到數據;另一個辦法就是實現阻塞型I/O,在沒有數據可讀時讓用戶進程進入睡眠狀態並等待數據。
有幾種處理和喚醒的方法,都要處理同一個基本的數據類型——等待隊列(walt_queue_head_t),就是由正在等待某事件發生的進程組成的一個隊列。使用之前必須聲明和初始化,在驅動程序中是如下聲明的:
wait_queue_head_t read_Jqueue;
init_waitqueue_head(&read_queue);
可以調用如下函數之一讓進程進入睡眠狀態:
void wait_evet(wait_queue_head_ queue,int condition);
int wait_evem_interruptible(Walt_queue_hean_t queue,int condition);
這兩個函數把等待事件和測試事件是否發生合併起來。調用之後,進程會一直睡眠到C布爾表達式condition為真時為止。在驅動中的read函數中,判斷讀鏈表為空,就調用它進入睡眠:
while(1ist_efnpty(&read_list)){
If(filp一>f_flags δO_NoNBLOCK)/*如果設置成非阻塞I/o*/
return—EAGAIN;
if(wait_evert_interruptible(read_queue,!list_empty(δread_list))) return—ERESTARTSYS;
}
對應上面的函數,要喚醒進程可以調用下面的函數:
wake_up(wait_queue_gead_t*queue);
wake_up_jnterruptlbk(wait_queue_head_t*queue);
驅動程序應該在數據到來后及時喚醒進程,也就是從FIFO讀取數據后,在退出底半部處理程序前執行:
wake_up_mterIuptible(&read_queue);
要指出的是被喚醒並不保證等待的事件發生了,所以從睡眠態返回后,應該循環測試condition。
②當read操作正在訪問某一個鏈表時,底半程序也要訪問同一個鏈表。這樣是比較危險的,應該避免。
為了避免這種情況的發生,這裡使用自旋鎖。在read操作訪問鏈表前獲得鎖,訪問結束時解鎖。底半部要訪問鏈表時先要檢查自旋鎖是否已上鎖,如果有,則等待到鎖可用。
自旋鎖使用類型spinlock_t來描述。自旋鎖被聲明和初始化為不加鎖狀態方式如下:
spinlock_t1ist_10ck=SPIN_LoCK_UNLOCKED;
處理自旋鎖的函數如下:
spill_1ock_bh(Spllalock-t*1ock);
spin_unloek_bh(splnlock_t*lock);
這裡使用獲得自旋鎖並且阻止底半部執行的函數,就可以完全保證底半部程序不會在read操作訪問鏈表時來訪問鏈表。程序中如下實現:
spln_lock_bh(&list_lock);
list_del(readl); /*將使用后的緩衝塊從讀鏈表中刪除*/
list_add_tail(readI,&free_list);/*將使用后的緩衝塊插入自由鏈表中*/
spin_unlock_bh(&list_lock);
2.5中斷驅動的I/O
至此,可以完整地描述ARM與FPGA之間數據流動的過程:當FPGA的一個FIFO滿后,向ARM發出中斷,ARM進入中斷處理程序后,讀取FPGA中的FlFO狀態寄存器(fpga_imf)的值,然後把一個任務插到立即隊列(tq_imrnediate)中,啟動底半部分(BH),同時將FIFO)狀態寄存器的值傳遞給底半部分處理程序(fpga_bh),完成這些工作後退出中斷處理程序。進入底半部分處理程序后,根據FIFO狀態寄存器的值確定要處理的F1F0。從FIFO中將數據讀出存人到內核緩衝塊中,這個緩衝塊可能是從自由隊列(free_list)中取出來的一個。如果自由隊列中是空的,就新分配一個緩衝塊。接下來將填好的緩衝塊加到讀隊列(read-list)中,並喚醒睡眠的進程,這樣底半部分的工作也完成了。當用戶進程對FPGA設備進行讀操作時,驅動中的read函數檢查讀鏈表。如果讀鏈表為空,則進入睡眠並等待數據到來。有數據后將從讀隊列中取出的緩衝塊的數據拷貝到用戶空間,然後將使用過的緩衝塊插到自由隊列中,等待以後再次使用。內核緩衝區的操作過程如圖3所示。圖3上半部分是在底半部分程序中,下半部分是在read函數中。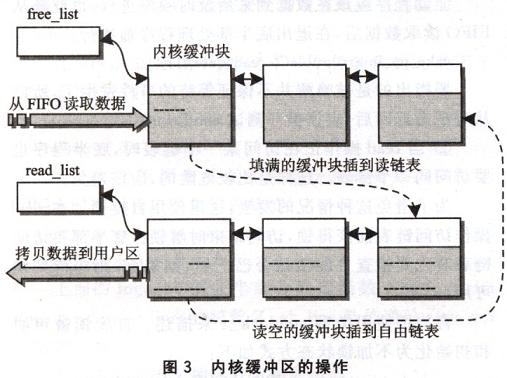
結語
連續數據流設備在uClinux下的驅動,通常會用到中斷機制。本文討論的中斷驅動的I/O式為這種應用提供了一種實用的方法。文中所涉及的鏈表、阻塞型I/O、自旋鎖等技術在驅動程序的開發中也經常得到使用。
[admin via 研發互助社區 ] uClinux下中斷驅動的I/O方式已經有6664次圍觀
http://cocdig.com/docs/show-post-42435.html
