PLD的重新定義PLD是什麼,Programmable Logic Device. 當然今天應該換個稱呼了:Processor+ Logic+DSP了,世界就是這樣不停的變化來維持他的穩定。
表1列出了Altera®可編程解決方案的主要歷史創新發展過程。,可以看到在2000年的時候,FPGA的廠商已經開始在嵌入式微處理器方面開始嶄露頭腳。 當然起初引來的也有一片嘩然。 說效率低下,難以開發。 新鮮事物的誕生總是要經過這樣的陣痛期。
在2002年,就有眾多廠家出來聲稱都支持嵌入式軟核CPU。 甚至也和當時流行的8051 turbo以及一些ARM進行比較。
| 年度 | 技術發展里程碑 | 在PLD業界的率先創新 |
| 2008 | Stratix ® IV FPGA | 業界的首款40-nm FPGA,具有最高的密度、最好的性能、最低的功耗、最大的收發器帶寬(高達8.5-Gbps 的收發器),並為PCI Express Gen 1/2提供硬核知識產權(IP)模塊。 |
| 2007 | ArriaTM GX FPGAs | 業界的首款低成本,基於收發器的中端,協議優化的FPGA。 |
| 2007 | Cyclone® III FPGA | 業界的首款低成本65nm FPGA,前所未有地同時實現了低功耗、低成本和高性能。 |
| 2006 | Stratix III FPGA | 65nm FPGA以更高的密度和性能支持高級集成,實現更複雜的產品。 |
| 2006 | Quartus® II 軟體 | 自然支持SDC設計約束 |
| 2006 | C2H 編譯器 | 嵌入式處理器的首款自動ANSI C至寄存器級(RTL)生成工具 |
| 2006 | Stratix II GX FPGA | 速度最快,密度最大的90nm FPGA架構,含有工作在622Mbps至6.375Gbps的20個低功耗收發器。 |
| 2005 | HardCopy® II 結構化 ASIC | 精細粒度體系結構;從90nm Stratix II FGPA原型無縫移植。 |
| 2005 | Cyclone II FPGA | 90nm FPGA,業界首款低成本FPGA,成本降低30%,密度提高3倍。 |
| 2004 | Stratix II FPGA | 90nm FPGA,含有名為ALM的8輸入“分段式”查找表(LUT),以此替代了4輸入LUT體系結構。 |
| 2003 | Quartus II 軟體 | 可編程邏輯軟體包,提供Tcl腳本支持。 |
| 2003 | Stratix GX FPGA | 0.13µm FPGA,分塊收發器體系結構。 |
| 2003 | HardCopy 結構化 ASIC | 業界唯一原型至量產0.13µm的完整解決方案 |
| 2003 | Stratix FPGA | 0.13µm、300mm、高速高密度FPGA |
| 2002 | Quartus II 軟體 | 可編程邏輯設計工具包,支持Linux。 |
| 2002 | Cyclone FPGA | 世界上成本最低的FPGA(0.13µm) |
| 2002 | SOPC Builder | 第一款FPGA自動系統生成工具 |
| 2002 | Stratix FPGA | 世界上第一款帶有嵌入式DSP模塊的FPGA |
| 2001 | HardCopy APEX TM 結構化 ASIC | FPGA 首次無縫移植至低成本結構化ASIC |
| 2001 | 系統互聯架構 | 第一款自動生成的互聯架構,支持同時主機/從機操作。 |
| 2001 | Quartus II 軟體 | 推出Quartus II 設計軟體 |
| 2001 | MercuryTM FPGA | 世界上第一款帶有嵌入式收發器的0.18µm FPGA |
| 2000 | 基於 ARM® 的 Excalibur TM 器件 | 世界上第一款帶有硬體嵌入式處理器的 FPGA |
| 2000 | Nios® 嵌入式處理器 | 世界上第一款嵌入式處理器,適合可編程邏輯應用。 |
處理器嵌入在FPGA中,需要什麼樣的溫床?
的確,在推出Nios soft processor 兩年之後,在我們周邊也開始陸續有開始吃螃蟹的了。 但是,還是回到結構的老話題上,來談論一下為什麼這個時候出現了由FPGA製造商推出的CPU,實際上在1997年,就已經有什麼FPGACPU的說法甚囂塵上。 而且也有人在Xilinx和Altera上面分別實現了原形。
開始在FPGA嵌入大塊RAM的時候,很多人抨擊這種結構,只是一個動物園裡面的老虎,實際上就是和貓差不多的殺傷力。 不可以否認,它不如分散式RAM來的靈活,但是它可以作為一些Cache,或者是緊耦合的RAM,還有就是它的規模在容量增加的時候,仍舊有很好的速度,那就可以作為CPU的Cache了。 Altera的RAM都是做在同一列的,很方便級聯。 另外匯流排寬度也很容易更改。
還有就是CPU裡面總是有很多匯流排,內部匯流排。 由於豐富的行聯線的存在,在幾列行資源里,就可以輕鬆集成RAM,CPU要的邏輯資源,以及匯流排的結構。 這樣,CPU也就順利的在FPGA的世界里粉墨登場了。 雖然起初只是16bit的。
2002年,Altera的開發軟體已經趨於穩定,可以說已經很適合自己產品的結構,而且布線效率非常高。同時Altera的Nios也上升為NiosII,這個時候NiosII已經蛻變為美麗蝴蝶---一個32bit的RISC CPU。 而且Altera又採用了非對稱的機構實現了革命性的Avlon互聯體系。 關於這個體系的由非對稱可以覆蓋對稱的,或不對稱性的應用,我們以後詳細聊。 總而言之。 如果再有一款更好結構的低成本的FPGA,那無異於在FPGA市場上颳起一場颶風!
Xilinx有Microblaze,其他的有ARM的核,實際上FPGA上實現的CPU,不是由一個CPU的內核來決定他的應用,而是誰有最好的互聯體系,能和外圍設備,和FPGA中的RAM,乘法器,以及其他定製邏輯更好橋接,粘合成一個SOPC,那才是真正意思上的軟核。 那究竟什麼樣子才好呢?
如果有以上的特性,那相信留給設計者的只有是無限的遐想空間。
FPGA上的CPU,有太多的元素,你知道嗎?
我們從哪裡開始講呢,準備從算盤開始講CPU,很多人說,我是不是太無聊了呢?聽我明天說給你聽!看似簡單的算盤,絕對孕育著無比的大智慧。 看是簡單的Avalon,也同樣有很多玄機。 那就是變變變。
來自Xilinx的消息,關於CPU在FPGA設計中的一些預測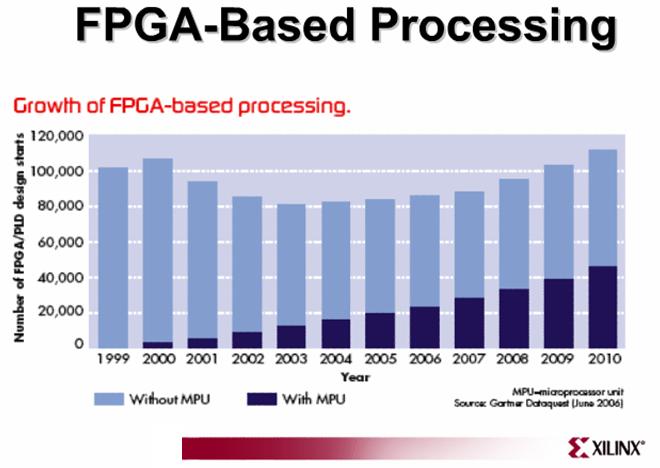
神奇的算盤
上回說到算盤。 實際上大家應該都見過這個了不起的發明,只是他出現在你的記憶中的次數越來越少,就忘記了,實際上,很多偉大之處在很早就有歷史可以證明的。 看看你平時見到的算盤。 
算盤的妙處和Altera的LE排列布局非常相似,或許是巧合吧。
但是這裡的偶然也有些必然。 或許我們有一天說,FPGA的結構最早是源於我國的。 哈哈,玩笑啊。
看一個更久的照片,當然這個也可以代表Cyclone的layout了。 
Avalon的奧秘
匯流排結構:
全交叉,部分交叉型(適合FPGA中的嵌入匯流排!)
Xilinx的是共享匯流排型。仍舊屬於傳統型設計,只是將其搬移到了FPGA中。 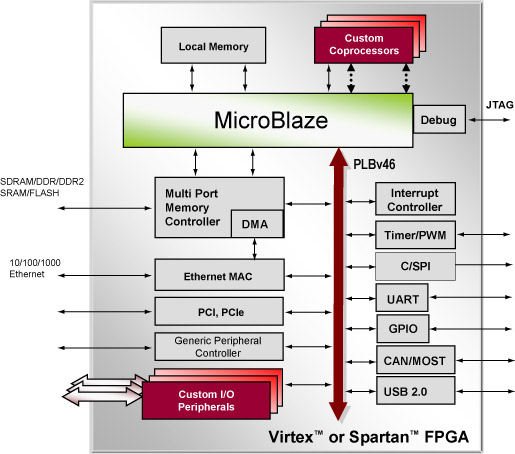
處理器介面主要抽象為:
回頭看Avalon: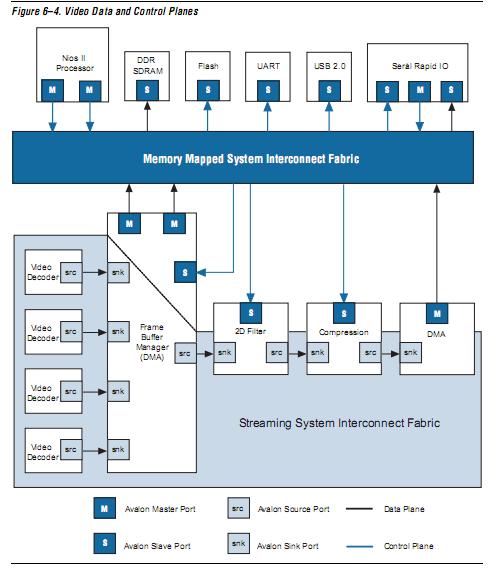
上面看起來,這兩個softcore都差不多,看了下面的特點,你就有答案了。
Selecting Hardware Architecture
Bus
Full Crossbar Switch-NiosII Avalon
Partial Crossbar Switch--Avalon is okey
Streaming-Avalon Streaming Map
Dynamic Bus Sizing
Understanding Concurrency
Create Multiple Masters
Create Separate Datapaths
Use DMA Engines
Include Multiple Master or Slave Ports
Create Separate Sub-Systems
Increasing Transfer Throughput
increasing the transfer efficienc
lower frequency devices can be used
Using Pipelined Transfers
Pipelined Read Masters
Increasing System Frequency
strategy
Tatic
Use Pipeline Bridges
Use a Clock Crossing Bridge
Consequences of Using Bridges
Reducing Logic Utilization
Reducing Power Utilization
Reduce Clock Speeds of Non-Critical Logic
Clock Crossing Bridge
Avalon-MM master ports operating at a higher frequency to slave ports running a a lower frequency
[admin via 研發互助社區 ] FPGA三國志-第三篇/SOPC篇已經有2652次圍觀
http://cocdig.com/docs/show-post-43031.html
