摘要:介紹了狀態機與PCI匯流排介面控制器的設計方法,探討了如何利用VHDL語言在可編程器件FPGA 中實現基本傳輸控制的PCI匯流排控制器。測試結果表明設計符合PCI規範的時序要求。
PCI匯流排是目前應用最廣泛的匯流排,它滿足了用戶對數據傳輸速率越來越高的要求。PCI局部匯流排是微型計算機中處理器/存儲器與外圍控制部件、擴展卡之間的互連介面。PCI匯流排規範是互連機構的協議,以及電氣和機械配置的規範,它可以在33MHz主頻32位數據通路的條件下達到峰值132Mbit/s的帶寬,在66 MHz主頻和64位數據通路的條件下達528 Mbit/s,這樣的數據帶寬突破了原有ISA,VME等匯流排的瓶頸,並且支持多匯流排主控和線性突發(burst)模式傳送,使其成為微型計算機事實上的匯流排標準,並在嵌入式計算機和工業控制計算機方面具有廣泛的應用前景。
1 用VHDL 實現PCI時序控制
在PCI匯流排的控制信號的控制下PCI匯流排上一般有3種交易:I/O讀寫、內存讀寫和配置寄存器(configuration register)讀寫,這3種交易一般都只
能進行單數據傳輸,也就是每次交易只傳輸一個數據(一個雙字、字或位元組),而對於內存讀寫則可以完成突發交易(burst transaction)。突發交易可以在每次交易中傳輸一批數據,這時每個時鐘都可以傳輸一個數據。在突發傳輸模式下的傳輸帶寬可以達到PCI匯流排的理論最高帶寬。一般發起交易(傳輸)的設備為主設備(initiator),交易(傳輸)的對象,也是傳輸的響應者為目標設備(target)。通常主設備得到匯流排所有權后發起交易,而目標設備確認自己為交易的對象后響應交易,從而配合主設備完成所有數據的傳輸。
PCI匯流排介面相對其它匯流排介面來說是比較複雜的,它不但有著嚴格的同步時序要求,而且為了實現即插即用和自動配置,PCI介面還必須有許多配置寄存器。為了實現PCI匯流排各控制信號間的時序關係,可以根據具體的交易設計相應的狀態機。
以目標設備I/O寫為例:當幀有效信號(FRAME#)為有效(低電平)時,讀傳輸開始,C/BE#[3:0]為“0011”,表明此交易為I/O寫,同時AD[31:0]上的數據為此次交易的I/O地址。如果此I/O地址與我們設備配置寄存器中I/O基地址寄存器(base address register)的值相同,我們的目標設備就要通過使DESEL#有效來聲明這次交易 作為主設備在有效FRAME#、I/O地址和C/BE#后,就在AD[31:0]上驅動要傳輸的數據,在C/BE#上驅動位元組使能、同時使能目標準備好信號IRDY#,直到檢測到目標設備有效的DRDY#信號后,此次交易中的主設備和目標設備就停止驅動各種信號。而目標沒備在準備好接收數據后就可以使能DRDY#,此後目標設備檢測到IRDY#時,就可以根據具體的位元組使能C/BE#[3:0],將AD[31:0]匯流排上的數據進行鎖存,從而完成整個交易。此交易的狀態機如圖1所示。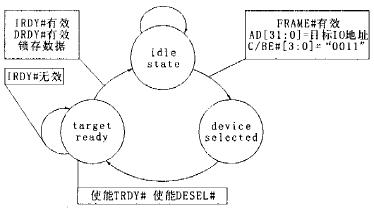
圖1 目標設備I/O 寫狀態機
下面是描寫狀態機的核心源程序,採用VHDL語言描述。
if state=idle_state
and pci_frame='0'
and pci_ad(31 downto 4) =pci_bar0;--pci_bar0為I/O基地址寄存器
and pci_c_be="0011" --I/O讀寫命令
then stated <= device_selected;
elsif state= device_selected --在此可以插入一個等待周期,以準備接收數據
then stated <= target_ready;
elsif state= target_ready
and pei_irdy= '0'
then stated <= idle_state;
end if;
在此狀態機的各種狀態下,使能相應地控制信號,利用該有限狀態機可以完成配置寄存器、存儲器,從而完成整個目標設備I/O寫交易。對於其它交易的狀態圖,根據具體的時序關係可以很容易在此基礎上實現。
2 測試結果
為了實現和驗證PCI控制邏輯,我們選用了Xilinx 公 司 的 Virtex 系 列 FPGA:XCV400HQ240。由於Virtex系列FPGA的管腳電氣特性與PCI規範中的要求相兼容,所以設計者只要考慮能不能滿足PCI的時序要求和時間要求就可以了。另外由於FPGA 中各種可編程資源豐富,可以很方便地實現配合PCI傳輸所需的FIFO,雙口RAM等,從而大大提高了匯流排控制的靈活性,同時也提高了整體性能。
上述器件中,實現PCI主/目標設備的配置寄存器讀寫、I/O讀寫、內存讀寫都相對簡單,並且在Windows操作系統下的調試也相對簡單。在調試過程中,採錄的目標設備I/O單數據讀寫時序圖的控制信號時序在示波器上的截圖如圖2,圖3所示。
從測試波形來看,完全符合PCI規範要求的時序。
在實際應用過程中,我們實現了一個PCI匯流排控制邏輯,並且在自製的雷達信號處理卡上得到了應用,其中實現的功能包括:配置空間讀寫、目標設備I/O讀寫和主設備DMA控制。在包括了一些供模擬的信號和32 bit寬深度為16的FIFO的情況下,總共所用的資源為429個SLICE(FPGA 內可編程宏單元)。實際調試中,DMA傳輸的穩定傳輸速度已能達到33 MHz,32 Bit的最高帶寬132 MB/s,完全滿足應用要求。
如果使用PCI的IP CORE(xi1inx公司的為專用器件(邏輯)設計的軟體包,有些為免費的,PCI CORE不免費),實現PCI標準介面控制邏輯所用
資源為400 SLICE左右。由此可見,自己設計的邏輯所耗的資源與專用的邏輯不會相差太大,甚至可以更少,而其靈活性是顯而易見的。
3 結束語
PCI匯流排以其優異的特性解決了外設和主機之間數據傳輸的瓶頸問題,因此在當前對匯流排帶寬要求越來越高的情況下,PCI匯流排將得到更加廣泛的應用。如果掌握了PCI匯流排控制邏輯的實現,就可在大規模可編程器件中發揮其方便、靈活和快捷的特長。這樣既可以避免專用晶元或IP CORE的靈活性低、不方便的缺點,又可以節省印製版空問、可編程資源,從而降低系統成本。並且可以很方便地移植到其它可編程器件上,具有較強的實用價值。如果具體輔助邏輯(如FIFO,雙口RAM)的設計可以和驅動程序的設計結合起來,將使驅動程序和硬體設備很好的結合,一方面可以提高邏輯設計和驅動程序設計的靈活性,又可以提高資源的利用率和系統的整體性能。
[admin via 研發互助社區 ] 利用FPGA實現PCI介面技術研究已經有2018次圍觀
http://cocdig.com/docs/show-post-43158.html
